Oracle, MySQL, Cassandra, Hadoop Database Training Classes in Mishawaka, Indiana
Learn Oracle, MySQL, Cassandra, Hadoop Database in Mishawaka, Indiana and surrounding areas via our hands-on, expert led courses. All of our classes either are offered on an onsite, online or public instructor led basis. Here is a list of our current Oracle, MySQL, Cassandra, Hadoop Database related training offerings in Mishawaka, Indiana: Oracle, MySQL, Cassandra, Hadoop Database Training
Oracle, MySQL, Cassandra, Hadoop Database Training Catalog
subcategories
Cassandra Classes
Hadoop Classes
Linux Unix Classes
Microsoft Development Classes
MySQL Classes
Oracle Classes
SQL Server Classes
Course Directory [training on all levels]
- .NET Classes
- Agile/Scrum Classes
- Ajax Classes
- Android and iPhone Programming Classes
- Blaze Advisor Classes
- C Programming Classes
- C# Programming Classes
- C++ Programming Classes
- Cisco Classes
- Cloud Classes
- CompTIA Classes
- Crystal Reports Classes
- Design Patterns Classes
- DevOps Classes
- Foundations of Web Design & Web Authoring Classes
- Git, Jira, Wicket, Gradle, Tableau Classes
- IBM Classes
- Java Programming Classes
- JBoss Administration Classes
- JUnit, TDD, CPTC, Web Penetration Classes
- Linux Unix Classes
- Machine Learning Classes
- Microsoft Classes
- Microsoft Development Classes
- Microsoft SQL Server Classes
- Microsoft Team Foundation Server Classes
- Microsoft Windows Server Classes
- Oracle, MySQL, Cassandra, Hadoop Database Classes
- Perl Programming Classes
- Python Programming Classes
- Ruby Programming Classes
- Security Classes
- SharePoint Classes
- SOA Classes
- Tcl, Awk, Bash, Shell Classes
- UML Classes
- VMWare Classes
- Web Development Classes
- Web Services Classes
- Weblogic Administration Classes
- XML Classes
- RED HAT SATELLITE V6 (FOREMAN/KATELLO) ADMINISTRATION
24 June, 2024 - 27 June, 2024 - VMware vSphere 8.0 Boot Camp
10 June, 2024 - 14 June, 2024 - Introduction to Spring 5 (2022)
15 July, 2024 - 17 July, 2024 - Ruby Programming
19 August, 2024 - 21 August, 2024 - Introduction to Python 3.x
22 July, 2024 - 25 July, 2024 - See our complete public course listing
Blog Entries publications that: entertain, make you think, offer insight
Have you ever played a game on your iPhone and wondered how to share it with your friends? Of course, not everyone has iPhones, and they aren’t always watching the leaderboards on the Gaming app, provided by Apple. Well, guess what? You don’t have to take a whole other camera to take a picture of your iPhone to create a photo of that particular score you have achieved. All you have to do is simultaneously press the “Home Button” and the “Lock Button” on your iPhone. After that, your iPhone should consequently flash to white, as if it were snapping its shutter, and taking a picture. Afterwards, you should be able to find the picture in your Photo Albums and share it with your friends.
But, taking screenshots of your iPhone doesn’t always have to deal with your game scores, you can take screenshots of almost any happening on your phone and share it with people! Have you ever had a memorable texting conversation with your friend, where you mistyped something, and the conversation went haywire? Sharing it becomes easy by using this feature. Want to show how odd a website looks on your iPhone compared to looking at it on your computer, and give it to their support to fix it? Take a screenshot of it! The possibilities of this feature are endless, and can become timeless with a simple picture.
I will begin our blog on Java Tutorial with an incredibly important aspect of java development: memory management. The importance of this topic should not be minimized as an application's performance and footprint size are at stake.
From the outset, the Java Virtual Machine (JVM) manages memory via a mechanism known as Garbage Collection (GC). The Garbage collector
- Manages the heap memory. All obects are stored on the heap; therefore, all objects are managed. The keyword, new, allocates the requisite memory to instantiate an object and places the newly allocated memory on the heap. This object is marked as live until it is no longer being reference.
- Deallocates or reclaims those objects that are no longer being referened.
- Traditionally, employs a Mark and Sweep algorithm. In the mark phase, the collector identifies which objects are still alive. The sweep phase identifies objects that are no longer alive.
- Deallocates the memory of objects that are not marked as live.
- Is automatically run by the JVM and not explicitely called by the Java developer. Unlike languages such as C++, the Java developer has no explict control over memory management.
- Does not manage the stack. Local primitive types and local object references are not managed by the GC.
So if the Java developer has no control over memory management, why even worry about the GC? It turns out that memory management is an integral part of an application's performance, all things being equal. The more memory that is required for the application to run, the greater the likelihood that computational efficiency suffers. To that end, the developer has to take into account the amount of memory being allocated when writing code. This translates into the amount of heap memory being consumed.
Memory is split into two types: stack and heap. Stack memory is memory set aside for a thread of execution e.g. a function. When a function is called, a block of memory is reserved for those variables local to the function, provided that they are either a type of Java primitive or an object reference. Upon runtime completion of the function call, the reserved memory block is now available for the next thread of execution. Heap memory, on the otherhand, is dynamically allocated. That is, there is no set pattern for allocating or deallocating this memory. Therefore, keeping track or managing this type of memory is a complicated process. In Java, such memory is allocated when instantiating an object:
String s = new String(); // new operator being employed String m = "A String"; /* object instantiated by the JVM and then being set to a value. The JVM calls the new operator */
Information Technology is one of the most dynamic industries with new technologies surfacing frequently. In such a scenario, it can get intimidating for information technology professionals at all levels to keep abreast of the latest technology innovations worth investing time and resources into.
It can therefore get daunting for entry and mid-level IT professionals to decide which technologies they should potentially be developing skills. However, the biggest challenge comes for senior information technology professionals responsible for driving the IT strategy in their organizations.
It is therefore important to keep abreast of the latest technology trends and get them from reputable sources. Here are some of the ways to keep on top of the latest trends in Information Technology.
· Subscribe to leading Analyst Firms: If you work for a leading IT organization, chances are that you already have subscription to leading IT analyst firms notably Gartner and Forrester. These two firms are some of the most recognized analyst firms with extensive coverage on almost every enterprise technology including hardware and software. These Analyst firms frequently publish reports on global IT spending and trends that are based on primary research conducted on vendors and global CIOs & CTOs. However, subscription to these reports is very expensive and if you are a part of a small organization you may have issues securing access to these reports. One of the most important pieces of research published by these firms happens to be the Gartner Hype Cycle which plots leading technologies and their maturity curve.Even if you do not have access to Gartner research, you can hack your way by searching for “Gartner Hype Cycle” on Google Images and you will in most cases be able to see the plots similar to the one below
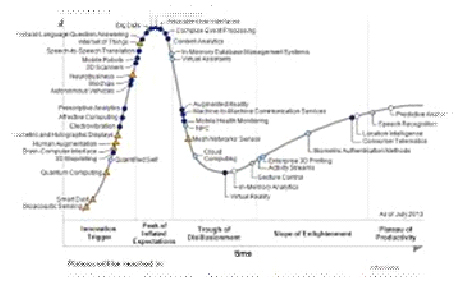
The original article was posted by Michael Veksler on Quora
A very well known fact is that code is written once, but it is read many times. This means that a good developer, in any language, writes understandable code. Writing understandable code is not always easy, and takes practice. The difficult part, is that you read what you have just written and it makes perfect sense to you, but a year later you curse the idiot who wrote that code, without realizing it was you.
The best way to learn how to write readable code, is to collaborate with others. Other people will spot badly written code, faster than the author. There are plenty of open source projects, which you can start working on and learn from more experienced programmers.
Readability is a tricky thing, and involves several aspects:
- Never surprise the reader of your code, even if it will be you a year from now. For example, don’t call a function max() when sometimes it returns the minimum().
- Be consistent, and use the same conventions throughout your code. Not only the same naming conventions, and the same indentation, but also the same semantics. If, for example, most of your functions return a negative value for failure and a positive for success, then avoid writing functions that return false on failure.
- Write short functions, so that they fit your screen. I hate strict rules, since there are always exceptions, but from my experience you can almost always write functions short enough to fit your screen. Throughout my carrier I had only a few cases when writing short function was either impossible, or resulted in much worse code.
- Use descriptive names, unless this is one of those standard names, such as i or it in a loop. Don’t make the name too long, on one hand, but don’t make it cryptic on the other.
- Define function names by what they do, not by what they are used for or how they are implemented. If you name functions by what they do, then code will be much more readable, and much more reusable.
- Avoid global state as much as you can. Global variables, and sometimes attributes in an object, are difficult to reason about. It is difficult to understand why such global state changes, when it does, and requires a lot of debugging.
- As Donald Knuth wrote in one of his papers: “Early optimization is the root of all evil”. Meaning, write for readability first, optimize later.
- The opposite of the previous rule: if you have an alternative which has similar readability, but lower complexity, use it. Also, if you have a polynomial alternative to your exponential algorithm (when N > 10), you should use that.
Use standard library whenever it makes your code shorter; don’t implement everything yourself. External libraries are more problematic, and are both good and bad. With external libraries, such as boost, you can save a lot of work. You should really learn boost, with the added benefit that the c++ standard gets more and more form boost. The negative with boost is that it changes over time, and code that works today may break tomorrow. Also, if you try to combine a third-party library, which uses a specific version of boost, it may break with your current version of boost. This does not happen often, but it may.
Don’t blindly use C++ standard library without understanding what it does - learn it. You look at std::vector::push_back()std::mapstd::unordered_map
Never call newdeletestd::make_uniqueusique_ptr, shared_ptr, weak_ptr
Every time you look at a new class or function, in boost or in std, ask yourself “why is it done this way and not another?”. It will help you understand trade-offs in software development, and will help you use the right tool for your job. Don’t be afraid to peek into the source of boost and the std, and try to understand how it works. It will not be easy, at first, but you will learn a lot.
Know what complexity is, and how to calculate it. Avoid exponential and cubic complexity, unless you know your N is very low, and will always stay low.
Learn data-structures and algorithms, and know them. Many people think that it is simply a wasted time, since all data-structures are implemented in standard libraries, but this is not as simple as that. By understanding data-structures, you’d find it easier to pick the right library. Also, believe it or now, after 25 years since I learned data-structures, I still use this knowledge. Half a year ago I had to implemented a hash table, since I needed fast serialization capability which the available libraries did not provide. Now I am writing some sort of interval-btree, since using std::map, for the same purpose, turned up to be very very slow, and the performance bottleneck of my code.
Notice that you can’t just find interval-btree on Wikipedia, or stack-overflow. The closest thing you can find is Interval tree, but it has some performance drawbacks. So how can you implement an interval-btree, unless you know what a btree is and what an interval-tree is? I strongly suggest, again, that you learn and remember data-structures.
These are the most important things, which will make you a better programmer. The other things will follow.
Tech Life in Indiana
training details locations, tags and why hsg
The Hartmann Software Group understands these issues and addresses them and others during any training engagement. Although no IT educational institution can guarantee career or application development success, HSG can get you closer to your goals at a far faster rate than self paced learning and, arguably, than the competition. Here are the reasons why we are so successful at teaching:
- Learn from the experts.
- We have provided software development and other IT related training to many major corporations in Indiana since 2002.
- Our educators have years of consulting and training experience; moreover, we require each trainer to have cross-discipline expertise i.e. be Java and .NET experts so that you get a broad understanding of how industry wide experts work and think.
- Discover tips and tricks about Oracle, MySQL, Cassandra, Hadoop Database programming
- Get your questions answered by easy to follow, organized Oracle, MySQL, Cassandra, Hadoop Database experts
- Get up to speed with vital Oracle, MySQL, Cassandra, Hadoop Database programming tools
- Save on travel expenses by learning right from your desk or home office. Enroll in an online instructor led class. Nearly all of our classes are offered in this way.
- Prepare to hit the ground running for a new job or a new position
- See the big picture and have the instructor fill in the gaps
- We teach with sophisticated learning tools and provide excellent supporting course material
- Books and course material are provided in advance
- Get a book of your choice from the HSG Store as a gift from us when you register for a class
- Gain a lot of practical skills in a short amount of time
- We teach what we know…software
- We care…
Interesting Reads Take a class with us and receive a book of your choosing for 50% off MSRP.













